[배경]
데이터베이스의 신뢰성과 성능을 높이기 위해 복제 디비, 다양한 DB 엔진, 쿼리 최적화 기술을 이해하는 것은 필수적입니다. 복제 디비를 통해 데이터의 가용성을 높이고, 다양한 DB 엔진의 특성을 이해하여 최적의 엔진을 선택하며, 쿼리 최적화를 통해 성능을 극대화하는 방법을 이 블로그에서 자세히 알아보세요.
[내용]
데이터베이스 복제(Replication)
1. 데이터베이스 복제의 사용 이유
먼저 기본적인 데이터 베이스를 구성할 때에는 아래의 그림처럼 하나의 서버와 Database를 구성하게 됩니다.

하지만 사용자는 점점 많아지고 Database는 많은 Query를 처리하기엔 과부화가 오다 보니 서버를 늘릴 필요성을 느끼게 됩니다. 서버의 사양을 높이기엔 비용의 문제가 있고 같은 서버의 분산하여 부하를 분산시키는 방법으로 데이터베이스 복제를 사용하게 되었습니다. 특히 Query의 대부분을 차지하는 Select를 어느 정도 해결하기 위해 Replication이란 방법이 나오게 되었습니다. 그리고 데이터의 손실이 발생했을때를 대비하여 백업을 하기 위해 데이터 베이스 복제를 합니다.
2. 데이터 베이스 복제의 정의
복제 데이터베이스(Replica Database)는 데이터베이스의 가용성과 성능을 향상시키기 위해 사용됩니다. 복제는 한 서버에서 다른 서버로 데이터베이스를 동기화시키는 기술입니다. 원본 데이터를 가진 서버를 소스 서버, 혹은 마스터 서버라고도 부르며, 복제된 데이터를 가진 서버를 레플리카 서버, 혹은 슬레이브 서버라고도 부릅니다.
3. 데이터 베이스 복제 동작 원리
MySQL 의 Replication 은 기본적으로 비동기 복제 방식을 사용하고 있습니다.
Master 노드에서 변경되는 데이터에 대한 이력을 로그(Binary Log)에 기록하면, Replication Master Thread 가 (비동기적으로) 이를 읽어서 Slave 쪽으로 전송하는 방식입니다.
MySQL 에서 Replication 을 위해 반드시 필요한 요소는 다음과 같습니다.
- Master 에서의 변경을 기록하기 위한 Binary Log
- Binary Log 를 읽어서 Slave 쪽으로 데이터를 전송하기 위한 Master Thread
- Slave 에서 데이터를 수신하여 Relay Log 에 기록하기 위한 I/O Thread
- Relay Log 를 읽어서 해당 데이터를 Slave 에 Apply(적용)하기 위한 SQL Thread
위의 구성 요소들은 아래 그림에서 보는 Flow 대로 데이터 복제를 수행합니다.
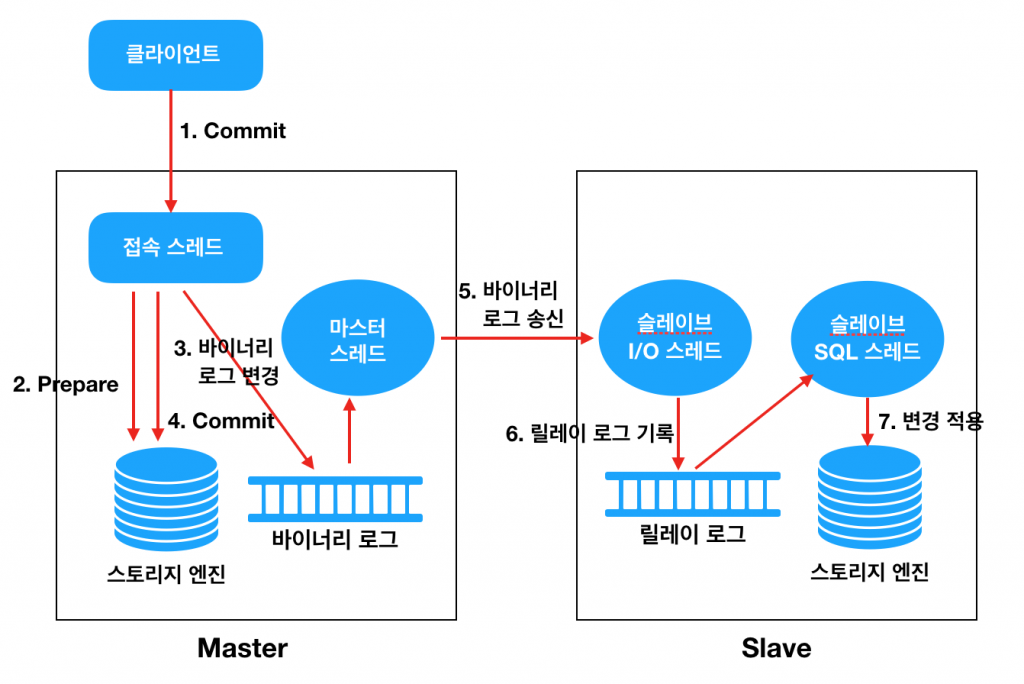
- 클라이언트(Application)에서 Commit 을 수행한다.
- Connection Thead 는 스토리지 엔진에게 해당 트랜잭션에 대한 Prepare(Commit 준비)를 수행한다.
- Commit 을 수행하기 전에 먼저 Binary Log 에 변경사항을 기록한다.
- 스토리지 엔진에게 트랜잭션 Commit 을 수행한다.
- Master Thread 는 시간에 구애받지 않고(비동기적으로) Binary Log 를 읽어서 Slave 로 전송한다.
- Slave 의 I/O Thread 는 Master 로부터 수신한 변경 데이터를 Relay Log 에 기록한다. (기록하는 방식은 Master 의 Binary Log 와 동일하다)
- Slave 의 SQL Thread 는 Relay Log 에 기록된 변경 데이터를 읽어서 스토리지 엔진에 적용한다.
데이터를 다른 노드로 복제해야 하는 상황에서 과연 SQL 을 전송하여 Replay 하는 방식으로 복제할 것인가, 또는 변경되는 Row 데이터를 전송하여 복제할 것인가가 고민거리입니다. 전자를 SBR(Statement Based Replication)이라고 하고, 후자를 RBR(Row Based Replication)이라고 합니다. SBR 은 로그의 크기가 작을 것이고, RBR 은 데이터 정합성에 있어서 유리할 것입니다. 사용자는 SQL 의 성격이나 변경 대상 데이터 양에 따라 SBR 또는 RBR 를 선택하여 사용할 수 있습니다.
SBR 과 RBR 을 자동으로 섞어서 사용할 수 있는 방식이 추가되었는데 이를 MBR(Mixed Based Replication)이라고 합니다. 평상 시에는 SBR 로 동작하다가 비결정성(Non-Deterministic) SQL 을 만나면 자동으로 RBR 방식으로 전환하여 기록하는 방식입니다. Binary Log 의 크기와 데이터의 정합성에 대한 장점을 모두 취한 방식이라고 보면 됩니다.
1) Master Thread
MySQL Replication 에서는 Slave Thread 가 Client 이고 Master Thread 가 Server 이다. 즉, Slave Thread 가 Master Thread 쪽으로 접속을 요청하기 때문에 Master 에는 Slaver Thread 가 로그인할 수 있는 계정과 권한(REPLICATION_SLAVE)이 필요합니다.
Master 쪽으로 동시에 다수의 Slave Thread 가 접속할 수 있으므로 Slave Thread 당 하나의 Master Thread 가 대응되어 생성됩니다. Master Thread 는 한가지 역할만을 수행하는데, 이는 Binary Log 를 읽어서 Slave 로 전송하는 것이다. 이 때문에 Binlog Sender 또는 Binlog Dump 라고도 불립니다.
Master 입장에서 Slave 의 접속은 여느 Client 의 접속과 다를 바가 없습니다. 따라서, 해당 접속이 Replication Slave Thread 로부터의 접속인지 일반 Application 의 접속인지 구분할 수 있는 방법이 없습니다. 로그인 과정도 일반 Client 와 동일하게 처리되기 때문입니다.
Master 가 특정 접속을 Slave Thread 로 인식하여 Binary Log 를 전송하려면, Slave 로부터의 특정 명령 Protocol 을 통해 '난 Replication Slave 야' 와 같이 알려주어야 합니다. Slave Thread 는 Master 에 접속 후 Binary Log 의 송신을 요청하는 명령어(Protocol)를 전송하는데 이는 COM_BINLOG_DUMP 와 COM_BINLOG_DUMP_GTID 입니다. 전자는 Binary Log 파일명과 포지션에 의해, 후자는 GTID 에 의해 Binary Log 의 포지션을 결정합니다.
Slave 는 위의 Protocol 을 통한(실제 SQL 은 아님) 소통 이후에 COM_QUERY 라는 Protocol 을 통해 실제 데이터(SQL) 송신을 요청하게 됩니다.
2) Slave I/O Thread
Slave I/O Thread 는 Master 로부터 연속적으로 수신한 데이터를 Relay Log 라는 로그 파일에 순차적으로 기록합니다. Relay Log 파일의 Format 은 Master 측의 Binary Log Format 과 정확하게 일치합니다. 인덱스 파일도 똑같이 존재하고 파일 명에 6 자리 숫자가 붙는 것도 동일합니다.
Relay Log 는 Replication 을 시작하면 자동으로 생성됩니다. Relay Log 의 내용을 확인하기 위해서는 SHOW RELAYLOG EVENTS 명령어를 사용합니다.
Relay Log 파일의 이름은 기본적으로 '호스트명-relay-bin' 이며, 이는 호스트 이름이 변경될 경우 오류가 발생할 수 있으므로 relay_log 옵션을 이용하여 사용자가 의도한대로 정하는 편이 좋습니다.
3) Slave SQL Thead
Slave SQL Thread 는 Relay Log 에 기록된 변경 데이터 내용을 읽어서 스토리지 엔진을 통해 Slave 측에 Replay(재생)하는 Thread 입니다. 아무래도 Relay Log 를 기록하는 I/O Thread 보다는 실제 DB 의 내용을 변경하는 SQL Thread 가 처리량과 연산이 많게 마련입니다.
이는 SQL Thread 가 Replication 처리의 병목 지점이 될 수 있다는 것을 의미합니다.
Master 측에서는 많은 수의 Thread 가 변경을 발생시키고 있는데 반해, Slave 에서는 하나의 SQL Thread 가 DB 반영 작업을 수행한다면 병목이 되는 것은 당연합니다. 이의 해결을 위해 등장한 것이 MySQL 5.7 에서 대폭 개선된 MTS(Multi Thread Slave)입니다. 이는 Slave 에서의 SQL Thread 가 병렬로 데이터베이스 갱신을 수행할 수 있도록 개선된 기능입니다.
데이터베이스 엔진(database engine) (=스토리지 엔진)
1. 데이터베이스 엔진의 정의
데이터베이스 엔진(database engine) 또는 스토리지 엔진(storage engine)은 데이터베이스 관리 시스템(DBMS)이 데이터베이스에 대해 데이터를 삽입, 추출, 업데이트 및 삭제(CRUD 참조)하는 데 사용하는 기본 소프트웨어 컴포넌트입니다. 데이터베이스 엔진을 조작할 때 DBMS 고유의 사용자 인터페이스를 이용하는 방법과 포트 번호를 통해 이용하는 방법이 있습니다. 대부분의 데이터베이스 관리시스템은 DBMS 의 사용자 인터페이스를 통하지 않고, 사용자가 내장된 엔진과 상호작용을 할 수 있는 자신만의 애플리케이션 프로그래밍 인터페이스(API)를 포함하고 있습니다. 데이터베이스 엔진이라는 용어는 종종 데이터베이스 서버 또는 데이터베이스 관리 시스템이라는 용어와 서로 바꾸어 사용되기도 합니다. 즉, 스토리지엔진의 특성에 따라 데이터 접근이 얼마나 빠른지, 얼마나 안정적인지, 트랜잭션 등의 기능을 제공하는지 등의 차이점이 발생합니다.
2. 데이터베이스 엔진의 역할

스토리지 엔진은 다음과 같은 역할을 하는 컴포넌트로 구성됩니다.
- 트랜잭션(transaction manager): 트랜잭션을 스케줄링하고 데이터베이스 상태의 논리적 일관성 보장합니다.
- 잠금 매니저(lock manager): 트랜잭션에서 접근하는 데이터베이스 객체에 대한 잠금을 제어. 동시 수행 작업이 물리적 데이터 무결성을 침해하지 않도록 합니다.
=> 트랜잭션과 잠금 매니저는 동시성 제어. 논리적 물리적 데이터 무결성을 보장하고, 동시 수행 작업의 효율적 수행을 담당합니다. - 엑세스 메서드(access method): 디스크에 저장된 데이터에 대한 접근 및 저장 방식을 정의. 힙 파일/B-트리/LSM 트리 등의 자료구조를 사용합니다.
- 버퍼 매니저(buffer manager): 데이터 페이지를 메모리에 캐시입니다.
- 복구 매니저(recovery manager): 로그를 유지 관리하고 장애 발생 시 시스템을 복구합니다.
3. 데이터베이스 엔진의 종류
1. MyISAM
- 정적인 데이터를 저장하고 자주 읽기 작업이 일어나는 테이블에 적합합니다.
- MySQL의 기본 스토리지 엔진
- 구조가 단순해, 속도가 빠릅니다.
- 데이터 저장에 실제적인 제한이 없고 매우 효율적으로 저장합니다.
→ 메모리 효율이 InnoDB보다 좋음 - 테이블 작업시 특정 행을 수정하려고 하면 테이블 전체에 락이 걸려서 다른사람이 작업 할 수 없습니다. (Table-level Lock)
→ 갱신이 많은 용도로는 성능적으로 불리. 동시 서비스에 적합X
→ multi-thread 환경에서는 성능이 저하. - 트랜잭션에 대한 지원이 없기때문에 작업도중 문제가 생겨도 이미 db안으로 데이터가 들어갑니다. DB 프로세스가 비정상 종료하면 테이블이 파손될 가능성이 높습니다. → 데이터 무결성이 보장되지 않습니다.
- 주로 Select 작업이 많은 경우에 사용됩니다. 즉, 읽기(READ)작업에 효과적입니다.
2. InnoDB
- 데이터 입력 및 수정이 빈번한 높은 퍼포먼스를 요구하고 다중 사용자, 동시성이 높은 OLTP 애플리케이션에 적합합니다. ('OLTP'는 여러 사용자가 실시간으로 DB Data를 갱신, 조회하는 단위 작업 처리하는 방식입니다.)
- MariaDB의 기본 스토리지 엔진
- MyISAM보다 데이터 저장비율이 낮고, 데이터 로드 속도가 느립니다.
- 레코드 기반의 락(Lock)을 제공합니다. 즉, 테이블 레벨이 아닌 ROW 레벨의 락을 지원합니다. 이로 인해 높은 동시성 처리가 가능한 특징이 있고 안정적입니다. (Row - level Lock)
→ insert,update,delete에 대한 속도가 빠름 - 외부키를 지원합니다.
- 자동 데드락 감지 : 감지 시 변경된 레코드가 가장 작은 트랜잭션을 롤백해버려서 데드락을 풀어줍니다.
- 자동 장애 복구 : 완료하지 못한 트랜잭션이나 일부만 기록되어 손상된 데이터 페이지 등을 자동 복구합니다.
- 데이터 무결성 보장(트랜잭션, 외래키, 제약조건, 동시성 등) - ACID
- Primary Key를 기준으로 Clustering되어서 저장됩니다. 즉, PK를 기준으로 순서대로 디스크에 저장되는 구조로 PK에 의한 Range Scan이 빠릅니다.
→ 데이터를 PK순서에 맞게 저장한다는 뜻이므로 order by 등 쿼리에 유리할 수 있습니다. - 인덱스와 더불어 데이터까지 버퍼풀에 저장하기 때문에 모든 데이터가 메모리에 있으면 디스크를 읽지 않아도 된다.
→ 데이터 접근 속도가 빠르다
→ 인덱스와 데이터 모두 메모리에 적재되므로 메모리 사용 효율에 좋지 않다.
→ 메모리 때문에 로그 수집에 대한 용도로 InnoDB를 사용하면 안됨.
3. Archive
- 로그 수집에 적합한 엔진입니다.
- 자동적으로 데이터 압축을 지원하며 다른 엔진에 비해 80% 저장공간 절약 효과를 자랑합니다.
- 데이터가 메모리상에서 압축되고 압축된 상태로 디스크에 저장되기 때문에 row-level locking이 가능합니다.
- 가장 빠른 데이터 로드 속도 또한 자랑하지만, INSERT와 SELECT만이 가능합니다.
- 트랜잭션은 지원하지 않습니다.
4. Cluster (NDB)
- 트랜잭션을 지원합니다.
- 모든 데이터와 인덱스가 메모리에 존재하여 매우 빠른 데이터 로드 속도를 자랑하며 PK 사용시 최상의 속도를 나타낼 수 있습니다.
쿼리 최적화
- SQL은 선언형 언어입니다. 각 쿼리는 SQL 엔진에게 우리가 무엇 을 원하는지 선언하지만 어떻게 하는지를 알려주지는 않기 때문입니다. 따라서, 어떻게 동작하는지 정의하는 "플랜(plan)" 은 쿼리의 효율성에 꽤나 중요한 영향을 미칩니다. 그럼 쿼리 최적화의 목적은 무엇일까요??
1. 쿼리 최적화의 목표
- 성능 향상(개선)
- 응답 시간 단축
- 기술 자원 보존
- 비용 절약
2. 쿼리 최적화의 방법
1. Select only the columns you need. (필요한 컬럼만 선택하라)
SELECT * FROM customers;데이터베이스에서 쿼리를 실행할 때 필요한 컬럼만 선택합니다.
SELECT name,age,city FROM customers;- 많은 필드 값을 불러올수록 DB는 더 많은 로드를 부담하게 되기 때문입니다. 칼럼 중에 불필요한 값을 가진 필드가 있다면 과감히 제외하고, 꼭 필요한 열만 불러오는 것이 좋습니다.
- 데이터 전송시 필요한 리소스를 절약하여 결과의 이해도를 높이고 전체적인 성능이 향상될 수 있습니다.
2. Use LIMIT to preview query results. (쿼리 결과를 미리보기 위해 Limit을 사용하라)
LIMIT을 활용합니다.
SELECT name FROM customers LIMIT 50;- LIMIT를 사용하여 반환되는 행의 수를 제한함으로써 네트워크를 통한 데이터 전송량을 줄이고 전체 쿼리 성능을 향상시킬 수 있습니다.
3. Use wildcards only at the end of a phrase. (와일드카드는 문장의 끝에서만 사용하라)
WHERE 절에 와일드카드가 있는 경우, 구문 맨 마지막에만 사용합니다.
SELECT name FROM customers WHERE state = 'A%';- 데이터베이스에서 인덱스는 주로 값의 시작 부분에 대해 최적화되어 있습니다. 와일드카드를 구문의 끝에만 사용하면 인덱스를 효과적으로 활용할 수 있습니다. 데이터베이스는 와일드카드가 문장의 끝에 있는 경우 더 효율적인 검색 방법을 선택할 수 있으며, 인덱스를 효과적으로 활용하여 쿼리의 실행 계획을 최적화할 수 있습니다.
4. Avoid SELECT DISTINCT if possible. (가능하면 SELECT DISTINCT 문을 피하라)
중복된 값을 제거하기 위해 추가적인 처리 부담(많은 처리 능력을 요구)을 주어 성능 저하를 초래할 수 있습니다.
SELECT DISTINCT name, age FROM customers;원하는 고유한 결과를 제공하기 위해 충분한 컬럼 값을 선택합니다.
SELECT name,age,gender,city,state,zip FROM customers;또는 GROUP BY 절을 사용하여 중복된 값을 그룹화합니다. 이를 통해 중복된 값을 그룹 단위로 처리할 수 있고, SELECT 문에서 필요한 컬럼만 선택할 수 있습니다. (결과를 그룹화)
SELECT name,age FROM customers GROUP BY name,age;- SELECT DISTINCT는 중복된 결과를 제거하기 위해 추가 작업을 수행해야 합니다.(메모리 및 처리 능력을 필요) 결과 집합이 크거나 복잡한 경우에는 처리 시간이 증가할 수 있고, 쿼리의 복잡성이 높을수록 자원 사용량이 증가할 수 있습니다. 따라서 중복을 제거할 필요가 없는 경우에는 SELECT DISTINCT를 피함으로써 쿼리의 실행 시간을 단축시킬 수 있고, 불필요한 자원 소비를 줄일 수 있으며, 데이터베이스 서버의 성능을 향상시킬 수 있습니다.(자원 절약)
[결론]
데이터베이스 최적화는 단순한 기술 적용을 넘어서, 복제, 엔진 선택, 쿼리 최적화의 통합적 접근이 필요합니다. 각 요소가 상호작용하며 전체 시스템의 성능을 좌우하므로, 종합적인 전략이 필수적입니다. 데이터 베이스의 가연성과 백업의 안전성을 위해서 복제 디비를 사용합니다. 성능에 적합한 엔진전략을 세워 비용을 효율적으로 활용하며 최적의 쿼리 작성으로 서버의 성능을 향상시킬 수 있습니다. 이 블로그가 여러분의 데이터베이스 관리에 실질적인 도움이 되었기를 바랍니다.
[출처 및 참조]
- 최범균의 JSP 2.3 웹 프로그래밍: 기초부터 중급까지
- https://medium.com/watcha/%EC%BF%BC%EB%A6%AC-%EC%B5%9C%EC%A0%81%ED%99%94-%EC%B2%AB%EA%B1%B8%EC%9D%8C-%EB%B3%B4%EB%8B%A4-%EB%B9%A0%EB%A5%B8-%EC%BF%BC%EB%A6%AC%EB%A5%BC-%EC%9C%84%ED%95%9C-7%EA%B0%80%EC%A7%80-%EC%B2%B4%ED%81%AC-%EB%A6%AC%EC%8A%A4%ED%8A%B8-bafec9d2c073
- https://jhlee-developer.tistory.com/entry/MYSQL-SQL-%EC%BF%BC%EB%A6%AC%EB%AC%B8-%EC%B5%9C%EC%A0%81%ED%99%94-%ED%9A%A8%EC%9C%A8%EC%A0%81%EC%9D%B8-%EC%BF%BC%EB%A6%AC%EB%A5%BC-%EC%9C%84%ED%95%9C-%ED%8C%81
- https://thefif19wlsvy.tistory.com/26
'CS' 카테고리의 다른 글
| [CS] 깨진 창문 이론과 소프트웨어 테스트 (0) | 2024.07.15 |
|---|---|
| [Web] 웹 서버 vs. WAS: 당신의 프로젝트에 맞는 서버는? (0) | 2024.07.03 |
| [DB] 파티셔닝 vs 샤딩: 데이터베이스 성능을 높이는 최적의 선택은? (1) | 2024.07.01 |
| [DB] 데이터 베이스의 개념과 각각의 특징 (0) | 2024.06.26 |
| [CS] 캐시(Cashe), 인메모리 데이터 저장소 Redis, 캐시메모리 개념정리 (0) | 2024.06.24 |


